28.11.2025


Depth Anything 3 est un modèle d’IA développé par des chercheurs de l’équipe ByteDance Seed, une branche de ByteDance, la maison mère de TikTok.
Ce modèle que l’on nommera DA3 permet de reconstituer la géométrie 3D d’une scène à partir d’images 2D, et ce, quel que soit le nombre d’images ou la position des caméras.
Et c’est là qu’il devient vraiment intéressant. En effet, DA3 fonctionne même si l’orientation et la position des caméras, autrement dit les poses, ne sont pas connues.
Pour faire simple, DA3 peut “deviner” à quoi ressemble l’espace autour d’un objet ou d’une scène à partir de simples photos, sans avoir recours à des appareils spécialisés comme des capteurs LiDAR par exemple.
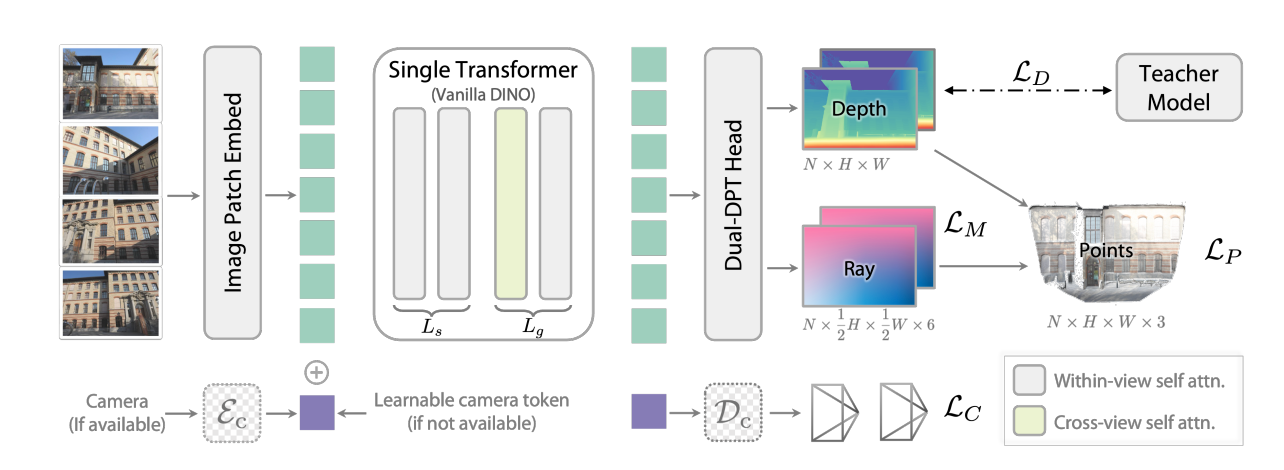
Techniquement, le projet Depth Anything V3 est très innovant : il repose sur un encodeur d’image standard (un DINOv2 “vanilla”), évitant les architectures 3D complexes habituelles.
Le cœur du modèle est la représentation “depth-ray”. Concrètement, le modèle prédit conjointement une carte de profondeur et une carte de rayons (la direction de la caméra pour chaque pixel). Ces deux objectifs semblent suffisants pour reconstruire la géométrie 3D à partir de n'importe quel nombre de vues, sans avoir à multiplier le nombre de tâches à l’entraînement.
Concernant l’entraînement, celui-ci utilise un paradigme Teacher-Student dans un but de distillation : un modèle géant (“professeur”) supervise un modèle plus petit (“étudiant”). En l’occurrence, un grand nombre de données synthétiques (plus fiables que les données réelles, souvent bruitées) sont utilisées pour guider l’apprentissage des cartes de profondeur.
Résultat : Depth Anything 3 atteint d’excellentes performances sur de nombreuses tâches sans être une usine à gaz. Rien que ça !
Pour évaluer les performances concrètes du modèles, les auteurs du projet ont aussi mis en place un nouveau benchmark, sobrement appelé “visual geometry benchmark”, qui évalue trois tâches distinctes mais tout à fait complémentaires :
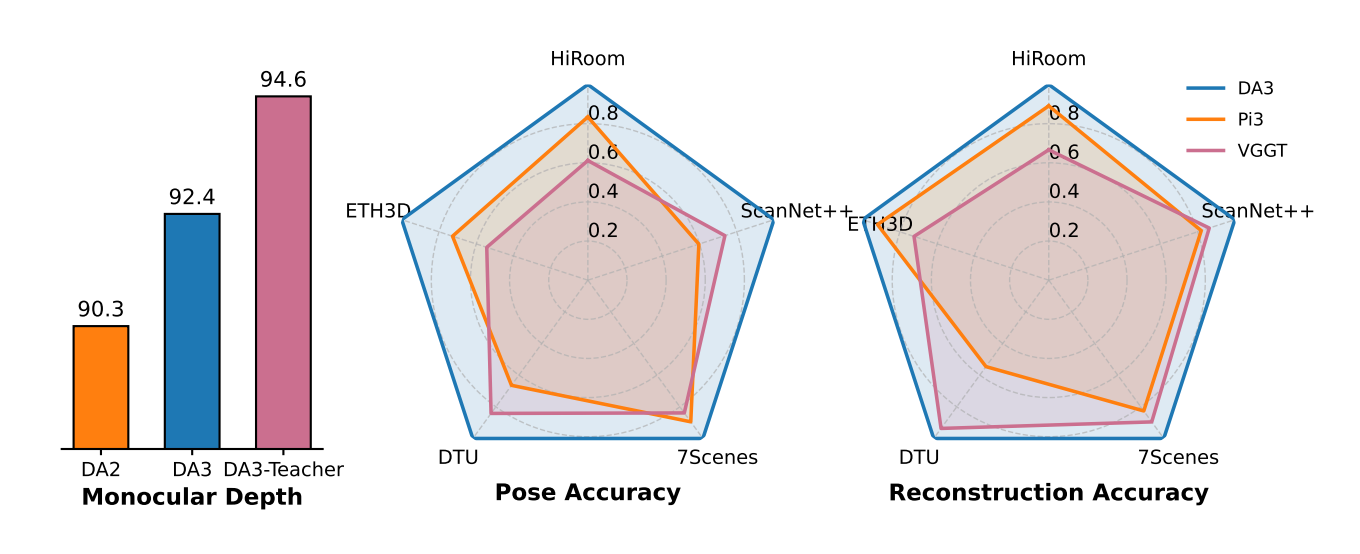
Sur ce benchmark, Depth Anything 3 établit un nouveau standard pour l’état-de-l’art. Sur certaines tâches, il bat à plate couture les modèles précédents et notamment VGGT avec, par exemple, + 35,7 % en précision de pose et + 23,6 % en précision géométrique selon leur site.
De plus, DA3 peut produire des représentations 3D utilisables ! En fixant l’encodeur, il est possible d’adapter la tête DPT (Dense Prediction Transformer) pour prédire des gaussiennes 3D (3D Gaussian Splatting), ce qui permet de faire du rendu de vues inédites, ou “Novel View Synthesis”. Autrement dit, DA3 peut générer de nouvelles vues à partir de caméras virtuelles.
Beaucoup de travaux en géométrie 3D ou estimation de profondeur nécessitent des architectures très spécialisées : réseaux convolutionnels 3D, pipelines complexes et spécifiques, têtes multiples, tâches auxiliaires… DA3 montre qu’on peut faire aussi bien, voire mieux, avec un modèle standard (DINOv2), associé à une seule tâche (depth-ray). Cette approche simplifie le travail à tous les niveaux : la conception, l’entraînement, l’adaptation à de nouveaux cas d’usages.
Le fait que Depth Anything 3 puisse fonctionner sans avoir besoin d’un gros volume d’images ni de connaître les poses de caméra est une avancée majeure.
Beaucoup de méthodes traditionnelles comme modernes exigent des séquences vidéo, des vues calibrées, ou des données de profondeur pour atteindre des performances similaires voire même en deçà. Ici, avec une vue unique, ou des vues non calibrées, le modèle parvient à reconstruire la scène avec une grande fiabilité.
Comme mentionné plus haut, DA3 établit un nouvel état de l’art, si nous nous basons sur le nouveau benchmark de géométrie visuelle proposé. Cela montre qu’une simplicité architecturale ne rime pas avec une perte de performance, c’est même tout le contraire ici.
La tête DPT, pour Dense Prediction Transformer, peut être adaptée à d’autres usages. Par exemple, avec une architecture GS-DPT, le modèle peut faire du rendu de vues inédites. Cela suggère que DA3 peut être utilisé non seulement pour obtenir des cartes de profondeur précises, mais aussi pour générer des scènes 3D que l’on peut “regarder” sous d’autres angles sans qu’ils soient couverts par des caméras.
Les auteurs affirment que tous leurs modèles sont entraînés uniquement sur des datasets académiques publics. Une accessibilité qui facilite la reproductibilité des résultats.
Les avancées scientifiques, c’est bien, mais quand elles trouvent des applications concrètes, c’est encore mieux. Et c’est le cas de DA3. Ce modèle ouvre la porte à de nombreuses applications dans l’industrie, la recherche ou des secteurs innovants. En voici quelques exemples concrets :
Sur le site du projet, les auteurs montrent que remplacer des composants de SLAM classiques par DA3 réduit le drift, c’est-à-dire l’erreur cumulative dans la localisation, même sur de grands environnements. DA3 peut donc renforcer la perception spatiale et améliorer la robustesse sans avoir recours à du matériel spécialisé, que ce soit pour des robots, des drones, des véhicules…
Dans des systèmes avec plusieurs caméras (par exemple, un véhicule autonome avec des caméras côté, avant, arrière), DA3 peut produire des cartes de profondeur stables, même si les vues ne se recouvrent pas forcément bien. Cela peut améliorer la compréhension de l’environnement autour du véhicule et donc sa sécurité.
Grâce au rendu obtenu via les gaussiennes 3D, DA3 peut être utilisé pour générer des images sous des angles non capturés initialement. Cela peut servir pour :
En architecture, immobilier, ou design d’intérieur, DA3 peut aider à reconstruire des plans 3D à partir de quelques photos, sans avoir besoin d’un scanner LiDAR coûteux. Cela peut accélérer la création de modèles 3D d’espaces pour la visualisation, la simulation ou la planification.
Dans des contextes de cartographie de terrains, d’infrastructures, de sites industriels ou sinistrés et accidentés, DA3 pourrait être utilisé avec des images prises par des drones ou des photographes pour générer jumeaux numériques cohérents, sans investir dans du matériel 3D coûteux.
Etant donné que DA3 peut fonctionner avec des images “ordinaires” (caméra de smartphone, webcam, etc.), elle peut permettre aux dispositifs mobiles de percevoir la profondeur sans capteur spécialisé. Par exemple, des applications de réalité augmentée pourraient générer des modèles 3D dynamiques à partir de simples photos prises par l’utilisateur.
Les chercheurs en vision par ordinateur, robotique ou géométrie 3D peuvent utiliser DA3 comme modèle de fondation pour d’autres travaux : par exemple, pour combiner la profondeur estimée avec des algorithmes de segmentation, de détection d’objets, ou d’optimisation de trajectoire.
En résumé, Depth Anything 3 est une avancée majeure dans le domaine de l’estimation de profondeur et de la reconstruction 3D : par sa simplicité architecturale, sa capacité à fonctionner avec des vues variées et non calibrées, et ses performances de pointe, il remet en question certaines idées reçues sur la nécessité de pipelines complexes pour produire une géométrie 3D précise. Une preuve que la performance ne réside pas forcément dans la complexité.
Ce type de modèle illustre parfaitement comment les modèles de fondations peuvent rendre accessibles des capacités de perception avancées, sans forcément recourir à du matériel coûteux.


